3. Принцип затухания частот Метод упорядочивания исторических текстов во времени
3. Принцип затухания частот
Метод упорядочивания исторических текстов во времени
Принцип затухания частот и основанный на нем метод был предложен и разработан А.Т. Фоменко.
Он позволяет находить хронологически правильный порядок отдельных фрагментов текста, обнаруживать в нем дубликаты на основе анализа, например, совокупности собственных имен, упомянутых в тексте. Как и в предыдущих методиках, мы стремимся к созданию метода датировки, основанного на численных, количественных характеристиках текстов и не обязательно требующего анализа смыслового содержания текстов, которое может быть весьма многозначно и расплывчато.
Если в документе упомянуты какие-либо «знаменитые», ранее известные нам персонажи, описанные в других, уже датированных хрониках, то это позволяет датировать описанные в тексте события. Однако если такое отождествление сразу не удается и если, кроме того, описаны события нескольких поколений с большим количеством ранее неизвестных действующих лиц, то задача установления тождества персонажей с ранее известными усложняется. Для краткости назовем фрагмент текста, описывающий события одного поколения, «главой-поколением».
Будем считать, что средняя длительность одного «поколения» — это средняя длительность правления реальных царей, упомянутых в дошедших до нас летописях. Эта средняя длительность правления царей была вычислена А.Т. Фоменко при обработке хронологических таблиц Блера. Она оказалась равной 17, 1 года.
При работе с реальными историческими текстами выделение в них «глав-поколений» иногда наталкивается на трудности. В таких случаях мы ограничивались лишь приблизительным разбиением текста на последовательные фрагменты. Пусть летопись X описывает события на достаточно большом интервале времени (А, В), на протяжении которого менялось по крайней мере несколько поколений персонажей. Пусть летопись X разбита на «главы-поколения» Х(Т), где Г — порядковый номер поколения, описанного во фрагменте Х(Т), в той нумерации «глав», которая фиксирована в тексте.
Возникает вопрос: правильно ли занумерованы, упорядочены эти «главы-поколения» в летописи? Или же если эта нумерация утрачена или сомнительна, то как ее восстановить? Другими словами, как правильно расположить во времени «главы» относительно друг друга? Оказывается, для реальных исторических текстов в подавляющем большинстве случаев выполняется следующая «формула»-правило: полное имя = персонаж. Это означает следующее.
Пусть интервал времени, описываемый летописцем, достаточно велик, например составляет несколько десятков или сотен лет. Тогда — как было проверено нами в результате анализа большого набора исторических документов — в подавляющем большинстве случаев разные персонажи имеют в одном и том же тексте разные полные имена. Полное имя может состоять из нескольких слов, например, Карл Плешивый.
Другими словами, число разных лиц с одинаковыми полными именами ничтожно мало по сравнению с количеством всех персонажей. Это верно для всех нескольких сотен исследованных нами исторических текстов, описывающих Рим, Грецию, Германию, Италию, Россию, Англию и т. д. Ничего удивительного в этом нет. В самом деле, летописец заинтересован в различении разных персонажей, чтобы избежать путаницы. Простейший способ добиться этого — присвоить разным лицам разные полные имена. Это простое психологическое обстоятельство и подтверждается подсчетами.
Сформулируем теперь принцип затухания частот, описывающий хронологически правильный порядок «глав-поколений».
При правильной нумерации «глав-поколений» летописец, переходя от описания одного поколения к следующему, сменяет и персонажей. А именно, при описании поколений, предшествующих поколению с номером Q, он ничего не говорит о персонажах этого поколения, так как они еще не родились. Затем, при описании поколения Q, летописец именно здесь больше всего говорит о персонажах этого поколения, поскольку с ними напрямую связаны описываемые им события. Наконец, переходя к описанию последующих поколений, летописец все реже и реже упоминает о прежних персонажах, так как описывает новые события, персонажи которых вытесняют умерших.
Здесь важно подчеркнуть, что мы имеем в виду не какие-то отдельные имена, а полный резервуар всех имен, использовавшихся в поколении с номером Q.
Вкратце наша модель формулируется так. Каждое поколение рождает новые исторические лица. При смене поколений эти лица сменяются.
Несмотря на внешнюю простоту, этот принцип оказался полезен при создании метода датировки. Принцип затухания частот имеет эквивалентную переформулировку. Так как персонажи практически однозначно определяются своими полными именами (имя = персонаж), то мы будем изучать резервуар всех полных имен текста. Термин «полное» будем обычно опускать, постоянно подразумевая его. Более того, оказалось, что подавляющее большинство исторических имен являются «простыми», состоящими из одного слова. Поэтому при обработке больших исторических текстов со значительным запасом имен можно рассматривать лишь «элементарные имена — кирпичи», разбивая редкие полные имена на отдельные составляющие их слова.
Рассмотрим группу всех имен, впервые появившихся в тексте, в «главе-поколении» с номером Q. Условно назовем эти имена Q-именами, а соответствующие им персонажи Q-персонажами. Количество всех упоминаний, с кратностями, всех этих имен в данной «главе» обозначим через K(Q, Q). Подсчитаем затем, сколько раз эти же имена упомянуты в «главе» с номером Т. Получившееся число обозначим через K(Q, 7).
При этом если одно и то же имя повторяется несколько раз, то есть с кратностью, то все эти упоминания подсчитываются. Построим график, отложив по горизонтали номера «глав», а по вертикали — числа K(Q, T), где номер Q фиксирован, а Г меняется. Для каждого Q мы получаем свой график. Принцип затухания частот тогда формулируется так.
При хронологически правильной нумерации «глав-поколений» каждый график К(Q, T) должен иметь следующий вид. Слева от точки Q график равен нулю, в точке Q — абсолютный максимум графика, потом график постепенно падает, более или менее монотонно затухает (рис. 5.12).
Этот график (на рис. 5.12) мы назовем идеальным.
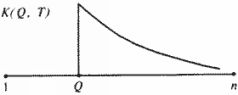
Рис. 5.12.
Сформулированный принцип должен быть проверен экспериментально. Если он верен и если «главы» в летописи упорядочены хронологически правильно, то все экспериментальные графики должны быть близки к идеальному. Проведенная экспериментальная проверка полностью подтвердила принцип затухания частот.
Всего нами было обработано несколько десятков больших исторических текстов. Во всех случаях, когда тексты описывают события эпохи XVI–XX веков, принцип затухания частот подтвердился. Отсюда вытекает методика хронологически правильного упорядочивания «глав-поколений» в тексте, или в наборе текстов, где этот порядок нарушен или неизвестен. Рассмотрим совокупность «глав-поколений» летописи X и занумеруем их в каком-нибудь порядке. Для каждой «главы» X(Q) подсчитаем число K(Q, T) при заданной нумерации «глав». Все числа K(Q, T), при переменных Q и Т, естественно организуются в квадратную матрицу К{T} размера n*n, где n — общее число «глав». В идеальном теоретическом случае частотная матрица К{T} имеет вид, показанный на рис. 5.13.
На рис. 5.13 ниже главной диагонали стоят нули, на главной диагонали расположен абсолютный максимум в каждой строке. Затем каждый график, в каждой строке, монотонно падает, затухает.
Оказывается, аналогичная картина затухания наблюдается и для столбцов матрицы. Это означает, что частота употребления в «главе» X(Q) имен более раннего происхождения «в среднем» тоже падает по мере удаления поколения Т, породившего эти имена, от фиксированного поколения Q.
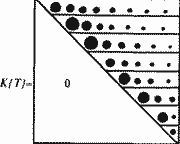
Рис. 5.13.
Для оценки скорости затухания частот удобно пользоваться усредненным графиком.
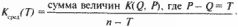
В этой формуле суммирование выполняется по всем парам (Q, Р), для которых разность Р — Q фиксирована и равна Т. Другими словами, график Ксред (T) получается усреднением матрицы К{Т} по ее диагоналям, параллельным главной. Он изображает «усредненную строку» или «усредненный столбец» частотной матрицы. Здесь Т изменяется от 0 до n — 1.
Конечно, экспериментальные графики могут не совпадать с теоретическим.
Если теперь изменить нумерацию «глав» в летописи, то изменятся и числа K(Q, T), поскольку возникает довольно сложное перераспределение «впервые появившихся имен». Следовательно, меняются частотная матрица К{T} и ее элементы. Будем менять порядок «глав» летописи с помощью различных перестановок s.
Каждый раз вычислим новую частотную матрицу K(sT), где sT — новая нумерация, соответствующая перестановке s. Будем искать такой порядок «глав» летописи, при котором все или почти все графики будут иметь вид, показанный на рис. 5.12. В этом случае экспериментальная частотная матрица K{sT} будет наиболее близка к теоретической матрице на рис. 5.13. Тот порядок «глав» летописи, при котором отклонение экспериментальной матрицы от «идеальной» будет наименьшим, и следует признать хронологически правильным и искомым.
Наш метод также позволяет датировать события. Пусть дан какой-то исторический текст Y, о котором известно только, что он рассказывает о неких событиях из эпохи (А, В), уже описанной в тексте X, разбитом на «главы-поколения», причем порядок этих «глав» в летописи X хронологически правилен. Как узнать, какое именно поколение описано в интересующем нас тексте Y? При этом мы хотим использовать только количественные характеристики текстов, не апеллируя к их смысловому содержанию, которое может быть разным или допускать сильно разнящиеся трактовки.
Ответ таков. Присоединим текст Y к совокупности «глав» хроники X, считая при этом У новой «главой» и приписав ей какой-то номер Q. Затем установим оптимальный, хронологически правильный порядок всех «глав» получившейся «летописи». При этом мы найдем правильное место и для новой «главы» Y. В простейшем случае, построив для нее график K(Q, T), можно добиться, меняя ее положение относительно других «глав», чтобы этот график был как можно ближе к идеальному. То положение, которое Y займет среди других «глав», и следует признать за искомое. Тем самым мы датируем события, описанные в Y.
Методика применима и тогда, когда рассматриваются не все имена, а только одно или несколько имен, например, какие-либо «знаменитые имена». Но в этом случае требуется дополнительный анализ, поскольку уменьшение числа используемых имен делает результаты неустойчивыми.
Метод был проверен на больших текстах с большим числом имен и с заранее известной достоверной датировкой. Во всех этих случаях эффективность метода подтвердилась.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКЧитайте также
6. 3. Принцип затухания частот. Методика правильного упорядочивания исторических текстов во времени
6. 3. Принцип затухания частот. Методика правильного упорядочивания исторических текстов во времени Эта методика позволяет находить хронологически правильный порядок отдельных фрагментов текста, обнаруживать в нем дубликаты на основе анализа, например, совокупности
1. Формулировка принципа затухания частот и дублирования частот. Примеры
1. Формулировка принципа затухания частот и дублирования частот. Примеры 1. 1. Формулировка принципа В работах [1]…[5] А. Т. Фоменко сформулировал фундаментальный принцип затухания частот, позволяющий строить естественные статистические модели эволюции во времени
3. 2. Принцип затухания частот и возраст имени
3. 2. Принцип затухания частот и возраст имени Предположим сначала, что рассматриваемый список имен Х – правильный, и в нем, согласно принципу затухания частот происходит естественная смена имен – новые имена возникают, а старые постепенно забываются. Кроме того, как
6.3. ПРИНЦИП ЗАТУХАНИЯ ЧАСТОТ. МЕТОДИКА ПРАВИЛЬНОГО УПОРЯДОЧЕНИЯ ИСТОРИЧЕСКИХ ТЕКСТОВ ВО ВРЕМЕНИ
6.3. ПРИНЦИП ЗАТУХАНИЯ ЧАСТОТ. МЕТОДИКА ПРАВИЛЬНОГО УПОРЯДОЧЕНИЯ ИСТОРИЧЕСКИХ ТЕКСТОВ ВО ВРЕМЕНИ Эта методика позволяет находить хронологически правильный порядок отдельных фрагментов текста, обнаруживать в нем дубликаты на основе анализа, например, совокупности
Принцип изменения во времени смысла исторических наименований и их географической локализации в допечатную эпоху
Принцип изменения во времени смысла исторических наименований и их географической локализации в допечатную эпоху Как уже понял читатель, одно из основных наших утверждений вкратце сводится к следующему. Многие исторические названия и понятия с течением времени
3. Принцип затухания частот Метод упорядочивания исторических текстов во времени
3. Принцип затухания частот Метод упорядочивания исторических текстов во времени Принцип затухания частот и основанный на нем метод был предложен и разработан А.Т. Фоменко.Он позволяет находить хронологически правильный порядок отдельных фрагментов текста,
4. Принцип дублирования частот Метод обнаружения дубликатов
4. Принцип дублирования частот Метод обнаружения дубликатов Настоящий метод является в некотором смысле частным случаем предыдущего, но ввиду важности для датировки мы выделили прием обнаружения дубликатов в отдельный раздел. Этот метод был предложен А.Т. Фоменко.
7.3. Принцип затухания частот. Методика правильного упорядочения исторических текстов во времени
7.3. Принцип затухания частот. Методика правильного упорядочения исторических текстов во времени Эта методика позволяет находить хронологически правильный порядок отдельных фрагментов текста, обнаруживать в нём дубликаты на основе анализа, например, совокупности
6. Принцип затухания частот Методика упорядочивания исторических текстов во времени
6. Принцип затухания частот Методика упорядочивания исторических текстов во времени Настоящая методика позволяет находить хронологически правильный порядок отдельных фрагментов текста, обнаруживать в нем дубликаты на основе анализа, например, совокупности
1. Функции объемов исторических текстов и принцип амплитудной корреляции
1. Функции объемов исторических текстов и принцип амплитудной корреляции В данном разделе цитируются фрагменты работы С.Т. Рачева и А.Т. Фоменко.(С.Т. Рачев, доктор физико-математических наук, профессор, специалист в области теории вероятностей и математической
2.8.3. Метод упорядочивания исторических текстов во времени
2.8.3. Метод упорядочивания исторических текстов во времени Данный метод позволяет находить хронологически правильный порядок отдельных фрагментов текста, обнаруживать в нем дубликаты на основе анализа, например, совокупности собственных имён, упомянутых
2.8.4. Метод датирования событий на основе принципа затухания частот.
2.8.4. Метод датирования событий на основе принципа затухания частот. Данный метод позволяет датировать события, описанные в каком–либо тексте в случае, когда время свершения этих событий неизвестно. Это — разновидность предыдущего метода упорядочивания исторических
2.8.7. Метод правильного хронологического упорядочивания и датировки древних географических карт
2.8.7. Метод правильного хронологического упорядочивания и датировки древних географических карт Суть метода основана на понимании того факта, что с развитием научных представлений о мире географические карты также должны улучшаться. Другими словами, количество
6. Принцип дублирования частот Метод обнаружения дубликатов
6. Принцип дублирования частот Метод обнаружения дубликатов Настоящий метод является в некотором смысле частным случаем предыдущего, но ввиду важности для датировки мы выделили прием обнаружения дубликатов в отдельный раздел. Этот метод предложен А.Т. Фоменко в [884], [886],
7.2. Обнаружение известных ранее дубликатов в Библии при помощи принципа затухания частот
7.2. Обнаружение известных ранее дубликатов в Библии при помощи принципа затухания частот В 1974–1979 годах В.П. Фоменко и Т.Г. Фоменко провели огромную работу по составлению полного списка всех имен Библии с учетом всех их кратностей и точным распределением упоминаний имен