2. Математическое описание связей между дубликатами в летописи
2. Математическое описание связей между дубликатами в летописи
Пусть дан хронологический список имен Х. Начиная с этого места забудем на время о разбиении списка Х на главы. В отличие от задачи определения величин сдвигов между дубликатами, для построения матрицы связей временная шкала в списке не используется. После построения матрицы мы снова воспользуемся ею для содержательной интерпретации результатов.
Для уточнения понятий «отрезок списка» и «близость в списке» введем следующие определения.
Определение.
Для i-го имени a_i в списке имен Х=a_1,…, a_n его определяющей окрестностью радиуса k назовем отрезок списка:
Д_a_i(k) = Д_i(k) = Д_i = a_i-k,…, a_i+k, (k? i? n-k).
Определяющая окрестность радиуса k не вводится для k первых и k последних имен списка. Число 2k+1, равное числу имен в определяющей окрестности, будем называть длиной этой окрестности.
Определение.
Ненормированной связью двух имен из множества I различных имен списка Х назовем число пар таких же имен, расположенных друг от друга в списке Х на расстоянии меньшем, чем p (то есть разность их номеров в списке меньше, чем p). Число p явяется параметром модели и называется длиной связывающей окрестности. Ненормированную связь имен u_i и u_j обозначим через l_0(u_i, u_j).
Параметры k и p подбирались в каждом случае отдельно с целью получить наиболее четкий результат. Оказалось однако, что изменение этих параметров для реальных хронологических списков имен слабо влияет на результат.
В частности, общая структура матрицы связей оставалась неизменной при всех рассмотренных значениях k и p (1«k«7, 3«p«17).
Ненормированная связь l_0(u_i, u_j) неудобна тем, что она не учитывает резких различий в кратностях вхождения имен в список Х, характерных для реальных хронологических списков. В то же время, часто употреблямые имена естественным образом должны в среднем чаще «случайно» сближаться в списке Х, чем имена более редкие. Чтобы исключить влияние кратности имен на их связь, введем следующее определение.
Определение. Пусть два имени u_i и u_j входят в список Х с кратностями k_i и k_j соответственно. Назовем нормированной связью этих имен (или просто – связью) число

Для уникального имени в списке (то есть при i=j, k_i=1) понятие связи такого имени с самим собой не вводится.
Поясним выбор нормировки в этом определении. Эта нормировка выбиралась так, чтобы связь любой пары имен из списка Х являлась бы случайной величиной со средним, не зависящим от выбора этой пары.
При этом предполагалось, что вероятностный механизм возникновения правильного хронологического списка Х таков, что при условии, что нам известно все множество имен списка, но неизвестен их порядок, все перестановки имен (все варианты выбора их порядка) равновероятны. Другими словами, мы вводим следующее предположение.
Предположение.
Знание лишь неупорядоченного множества имен правильного хронологического списка Х не может нести в себе никакой информации о порядке следования этих имен в списке Х.
В этом предположении справедлива следующая лемма.
Лемма 1.
Пусть дан правильный хронологический список Х. Предположим, что максимальная кратность имени в этом списке, а также параметр p (длина связывающей окрестности) много меньше длины списка Х. Тогда среднее значение ненормированной связи двух имен u_i и u_j, входящих в список Х с кратностями k_i и k_j соответственно, пропорционально числу
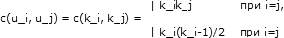
Доказательство.
а) Рассмотрим случай i=j. Схему равновероятных размещений имен в списке Х можно представить как итог последовательного размещения n имен по n местам в списке. При этом, каждое имя равновероятно занимает одно из оставшихся свободными мест. Очередность размещения имен может быть выбрана произвольно, но будучи выбранной должна быть фиксирована.
Поэтому можно считать, что перед размещением k_j экземпляров имени u_j все k_i экземпляров имени u_i уже размещены. По предположению, k_i, k_j, p«n (напомним, что n обозначает длину списка Х). Поэтому числом случаев, когда два экземпляра имени u_i оказались в списке Х рядом (на расстоянии, меньшем, чем p) можно пренебречь по сравнению с общим числом способов размещения k_i экземпляров имени u_i в списке Х.
Представим теперь размещение k_j экземпляров имени u_j в виде последовательности испытаний Бернулли, причем успехом в одном испытании будем считать попадание в связывающую окрестность к одному из уже размещенных экземпляров имени u_i. Тогда значение ненормированной связи l_0(u_i, u_j) равно числу успехов в этой схеме Бернулли.
Вероятность успеха в одном испытании при этом пропорциональна числу k_i уже размещенных имен u_i (точнее говоря, пренебрегая влиянием случайного перекрытия связывающих окрестностей этих имен, получаем, что эта вероятность равна 2pk_i/n). Общее количество испытаний при этом равно k_j. Среднее число успехов (=среднее значение ненормированной связи l_0(u_i, u_j)) пропорционально произведению вероятности успеха в одном испытании на число испытаний, то есть пропорционально k_ik_j. Это и утверждается в лемме.
б) Рассмотрим случай i=j. Выберем последовательность размещения имен таким образом, чтобы сначала размещались все k_i экземпляров имени u_i, а затем – все остальные имена. Пусть первый экземпляр имени u_i уже размещен. Вероятность того, что при размещении второго экземпляра он попадет в связывающую окрестность к уже размещенному первому экземпляру этого имени, равна 2p/n (здесь мы пренебрегаем вероятностью того, что первый экземпляр попал на самый край списка, и захват его связывающей окрестности оказался меньше, чем 2p, по сравнению с вероятностью того, что это не так).
Аналогично, пренебрегая малыми вероятностями перекрытий связывающих окрестностей (слагаемыми второго порядка), получаем, что третий экзеипляр имени u_i попадает в связывающую окрестность к одному из уже размещенных экземпляров с вероятностью 2(2p/n) и т. д. Для i-того экземпляра эта вероятность равно (i-1)2p/n.
Введем случайные величины h_i (2? i? k_i), положив по определению h_i=1 если i-й экземпляр имени u_i при своем размещении попал в связывающую окрестность к одному из уже размещенных (i-1) экземпляров этого имени, и h_i=0 иначе. Тогда, согласно приведенным рассуждениям,
Ph_i=1 = (i-1)2p/n, (2? i? k_i).
Заметим теперь, что число «встреч» имен u_i в списке Х (где под встречей понимается попадание пары имен в связывающую окрестность друг к другу) равняется сумме случайных величин h_i:
k_i
l_o(u_i, u_j) = S h_i.
i=2
Следовательно, математическое ожидание (среднее значение) связи l_0(u_i, u_j) равно
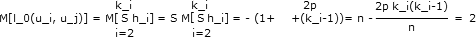
Дело в том, что математическое ожидание суммы случайных величин равно сумме их математических ожиданий,
а M[h_i] = Ph_i=1 = (i-1)2p/n.
Лемма доказана.
Следствие. Среднее значение связи l(u_i, u_j) двух имен, входящих в правильный хронологический список Х, не зависит от выбора пары имен (u_i, u_j) и, следовательно, является характеристикой списка Х и параметров модели.
Это среднее мы будем обозначать через а(Х). Из доказательства леммы следует, что а(Х) = 2p/n.
Генеральное (теоретическое) среднее а(Х) мы будем называть средним по размещениям в отличие от эмпирического среднего по матрице, получаемого усреднением фактических значений связи пар имен по всем парам имен, входящих в данный список Х.
Последнее название объясняется тем, что значения связи пар имен списка естественным образом составляют некоторую квадратую матрицу.
Замечание. Сформулированное выше предположение aposteriori подтверждается для реальных правильных хронологических списков (летописей) тем, что для них эмпирическое среднее по матрице практически совпадает с генеральным средним по размещениям а(Х) (вычисленным с помощью этого предположения).
Если же список содержит дубликаты, то для него, как показали расчеты, среднее по матрице обычно чуть больше, чем среднее по размещениям.
Но различие между этими величинами было невелико для всех рассмотренных нами реальных исторических списков. Это – отражение того обстоятельства, что даже в том случае, когда хронологический список имен содержит дубликаты, доля пар-дубликатов среди общего количества всех пар определяющих окрестностей, обычно невелика.
В соответствии с описанной в главе 1 моделью возникновения дубликатов в хронологический списках (см., например, модельную задачу о колодах карт), введем меру связи двух произвольных определяющих окрестностей Д_r, Д_s в списке Х.
Эта мера отражает количество «связывающих летописей» для данной пары отрезков списка, нормированное таким образом, чтобы при отсутствии дубликатов в списке, оно сохраняло бы приблизительно одно и то же значение для всех пар определяющих окрестностей списка Х.
Более точно, мера связи двух отрезков списка подбиралась таким образом, чтобы в случае правильного списка (который мы, в соответствии со сделанным предположением, рассматриваем как некоторый случайный элемент) среднее значение этой меры не зависело бы от выбора конкретной пары отрезков, то есть было бы единым для всего списка Х.
Определение.
Пусть дан хронологический список имен Х и фиксированы параметры модели k и p. Назовем связью двух определяющих окрестностей Д_r и Д_s списка Х число
r+k s+k
c
L_0(Д_r, Д_s) = – l(a_i, a_j).
(2k + 1)^2
i=r-k j=s-k
j=i
Здесь c – постоянная масштаба, задаваемая из соображений удобства вычислений (мы брали значение c=25).
Лемма 2.
Если хронологический список имен Х не содержит дубликатов (является правильным) и выполнены предположения Леммы 1, то среднее значение по размещениям для связи L_0(Д_r, Д_s) не зависит от Д_r и Д_s и равно cа(Х).
Доказательство.
Утверждение Леммы 2 следует из Леммы 1 и из того, что среднее значение суммы случайных величин равно сумме их средних значений. Заметим, что число слагаемых в двойной сумме, определяющей значение связи L_0(Д_r, Д_s), равно множителю (2k + 1)^2, стоящему в знаменателе. Следовательно, среднее значение по размещениям для связи L_0(Д_r, Д_s) равняется среднему значению по размещениям для связи l(a_i, a_j), умноженному на c, то есть равно cа(Х).
Лемма 2 доказана.
Более 800 000 книг и аудиокниг! 📚
Получи 2 месяца Литрес Подписки в подарок и наслаждайся неограниченным чтением
ПОЛУЧИТЬ ПОДАРОКДанный текст является ознакомительным фрагментом.
Читайте также
4. 6. Метод гистограмм частот разнесения связанных имен. Определяет величины сдвигов между дубликатами в хронологических списках
4. 6. Метод гистограмм частот разнесения связанных имен. Определяет величины сдвигов между дубликатами в хронологических списках Здесь мы на модельном примере изложим идею и основные шаги методики. На формальном уровне она изложена в главе 2.Обозначим буквой К большую
2. 5. Математическое описание списков имен с правильной хронологией
2. 5. Математическое описание списков имен с правильной хронологией Исследуем структуру хронологического списка Х, сравнивая распределение з с распределениями з2 и з3. Естественные представления о том, как должен быть устроен правильный хронологический
1. Как узнать – какие именно части летописи являются дубликатами?
1. Как узнать – какие именно части летописи являются дубликатами? В предыдущей главе с помощью гистограмм частот разнесений связанных имен проверялась гипотеза об отсутствии дубликатов в данном хронологическом списке имен.В тех случаях, когда присутствие дубликатов
4. 2. Гистограммы частот разнесений связанных имен в списке «АК». сдвиги между дубликатами
4. 2. Гистограммы частот разнесений связанных имен в списке «АК». сдвиги между дубликатами Гистограмма частот разнесений имен-ровесников для списка имен армянских католикосов приведена на рис. 49. На рис. 50 приведена для сравнения аналогичная гистограмма для разбиения
5. ОПИСАНИЕ ПАРАЛЛЕЛИЗМА МЕЖДУ РУСЬЮ-ОРДОЙ И «ЗАПАДНО-ЕВРОПЕЙСКИМИ» ГАБСБУРГАМИ-НОВГОРОДЦАМИ XIV–XVI ВЕКОВ
5. ОПИСАНИЕ ПАРАЛЛЕЛИЗМА МЕЖДУ РУСЬЮ-ОРДОЙ И «ЗАПАДНО-ЕВРОПЕЙСКИМИ» ГАБСБУРГАМИ-НОВГОРОДЦАМИ XIV–XVI ВЕКОВ 5.1. ВАСИЛИЙ I = «РУДОЛЬФ I» 1a. РУССКО-ОРДЫНСКАЯ ИМПЕРИЯ. ВАСИЛИЙ I КОСТРОМСКОЙ 1272–1277, правил 5 лет. Начало династии. ~ ~ ~ 1c. ГАБСБУРГИ. Начало империи Габсбургов
17.5. Летописное описание Святослава и гомеровское описание Ахиллеса
17.5. Летописное описание Святослава и гомеровское описание Ахиллеса Русская летопись говорит о личности Святослава следующее. «Бе во самъ храбръ и легко ходя, аки пардусъ, и войны многие творяше. Ходяа возовъ по себе не вожаше, ни котла, ни мяса варяше, но потонку мяса
6. Тур Хейердал доказывает существование родственных связей между «древними» викингами и русскими донскими казаками
6. Тур Хейердал доказывает существование родственных связей между «древними» викингами и русскими донскими казаками В 2001 году в газете «Аргументы и факты» (№ 16, 2001 г., с. 22) появилось сообщение под любопытным заголовком «Казаки — потомки викингов?». Приведем заметку
5. «Античные» события являются фантомными дубликатами, отражениями средневековых оригиналов
5. «Античные» события являются фантомными дубликатами, отражениями средневековых оригиналов Опишем подробнее фантомные блоки-эпохи в скалигеровской летописи Е, двигаясь слева направо по оси времени. Укажем также соответствующие хронологические вехи, то есть
17.5. Летописное описание Святослава и гомеровское описание Ахиллеса
17.5. Летописное описание Святослава и гомеровское описание Ахиллеса Русская летопись говорит о личности Святослава следующее. «Бе бо самъ храбръ и легко ходя, аки пардусъ, и войны многие творяше. Ходяа возовъ по себе не вожаше, ни котла, ни мяса варяше, но потонку мяса
7. Список фантомных «античных» событий, являющихся дубликатами средневековых оригиналов
7. Список фантомных «античных» событий, являющихся дубликатами средневековых оригиналов Опишем подробнее фантомные блоки-эпохи в скалигеровской летописи Е, двигаясь слева направо по оси времени. Укажем также соответствующие хронологические вехи, то есть
Приложение № 3 Описание Палестины. Описание островов Кипра, Родоса, Мальты
Приложение № 3 Описание Палестины. Описание островов Кипра, Родоса, Мальты В исходной электронной версии отсутствовало. (Прим. выполнившего
1. Низкая культура Рима в XII веке. — Законы Юстиниана. — Каноническое право. — Сборник Альбина. — liber censum Ченчия. — Продолжение книги пап. — Малое число римских историков. — Описание собора Св. Петра Маллия; описание Латерана Иоанна диакона
1. Низкая культура Рима в XII веке. — Законы Юстиниана. — Каноническое право. — Сборник Альбина. — liber censum Ченчия. — Продолжение книги пап. — Малое число римских историков. — Описание собора Св. Петра Маллия; описание Латерана Иоанна диакона В продолжение всего XII века
МАТЕМАТИЧЕСКОЕ УПРАЖНЕНИЕ В КАМНЕ
МАТЕМАТИЧЕСКОЕ УПРАЖНЕНИЕ В КАМНЕ Математическую закономерность в этих изображениях обнаружил Гвенк’хлан Ле Скуезек, бретонец, несомненный математический гений, хотя он скромно полагает, что послание, зашифрованное тысячелетия назад, понятно каждому1.Счет начинается,
7. Список «античных» событий, являющихся фантомными дубликатами, отражениями средневековых оригиналов
7. Список «античных» событий, являющихся фантомными дубликатами, отражениями средневековых оригиналов Опишем подробнее фантомные блоки-эпохи в скалигеровской летописи E, двигаясь слева направо по оси времени. Укажем также соответствующие хронологические вехи, то есть
6. Тур Хейердал доказывает существование родственных связей между «древними» викингами и русскими донскими казаками
6. Тур Хейердал доказывает существование родственных связей между «древними» викингами и русскими донскими казаками В 2001 году в газете «Аргументы и факты» (№ 16, 2001 г., стр. 22) появилось сообщение под любопытным заголовком «Казаки — потомки викингов?». Приведем заметку
Альмут Буес (Варшава-Берлин) Описание областей между Польшей и Московией в Записках Мартина Груневега
Альмут Буес (Варшава-Берлин) Описание областей между Польшей и Московией в Записках Мартина Груневега Имеющиеся в письменных источниках средневековья и раннего Нового времени (вплоть до XVI в.) географические сведения о регионах и населении Восточной Европы не